Welcome!
This is the official repository for StarChat --an Open Source, scalable conversational engine for B2B applications. You can find the code on our github repository.
How to contribute
To contribute to StarChat, please send us a pull request from your fork of this repository.
Our concise contribution guideline contains the bare minumum requirements of the code contributions.
Before contributing (or opening issues), you might want send us an email at starchat@getjenny.com.
Quick Start
1. Installation
The easiest way is to install StarChat using two docker images. You only need: docker docker compose
We have made available the containers needed for having StarChat up and running without local compiling: On container is for the Elasticsearch (version 7.0.0) image the other for the StarChat itself in the Java (8) image.
For instruction about docker installation on Ubuntu platform refer to docker for Ubuntu
1.1 Run Prebuilt Docker containers
To use them, you need to download Starchat Docker or simply type:
git clone https://github.com/GetJenny/starchat-docker.git
Get into the starchat-docker directory and:
docker-compose up -d
If you get an ERROR: Version in "./docker-compose.yml" is unsupported. you need to update docker-compose to the version indicated in the docker-compose.yml file. Note that it might not be available on old version of ubuntu (we need to use a very recent one). If that's the case see eg stackoverflow.
If you want to change default ports, eg because you have other services on 8888/9200/9300, change the values in docker-compose.yml.
To test elasticsearch and starchat started correctly you can send the following command
curl -X GET localhost:8888
If you don't get OK replay you can check the output logs of elasticsearch and start-chat starting the containers without detached mode option.
docker-compose up
Elasticsearch makes some boostrap check. If they failed elasiticsearch quits with message elastisearch exited with code 78.
Possible fails reason are:
1. max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
2. max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
have a look at troubleshooting in order to solve them.
StarChat supports the user authentication and the default Elasticsearch user used is the built-in user "elastic". The password can be changed using the following command from a running container:
docker exec -i -t docker-starchat_elasticsearch_1 /usr/share/elasticsearch/bin/elasticsearch-keystore add "bootstrap.password"
When using this command the file elasticsearch.keystore is updated. The password can be set even up on ES using a native user.
1.2 Elasticsearch Configuration
Now you need to configure Elastic search performing the following operations:
- Creating the system indices
- Creating the application indices
- Creating a new user associated with read/write privileges on the application indices
The three steps can be accomplished by running some scripts that can be found in the starchat-docker/scripts directory.
The scripts assume you are using the default port 8888 and the index based on english language. If you need to change these parameters edit accordingly the variabile PORT and INDEX_NAME you can find in the scripts
cd starchat/scripts/api_test
#System Indices creation (admin privileged execution)
./postSystemIndexManagementCreate.sh
./postLanguageIndexManagement.sh
#Application Indices creation (admin privileged execution)
./postIndexManagementCreate.sh
#User with creation (admin privileged execution)
./insertUser.sh
Scripts are based on RESTful API documented here.
1.3 Chat Decision Table Configuration
Now you have to load the configuration file for the actual chat, aka decision table. We have provided the example configuration file starchat-docker/scripts/decision_table_starchat_doc.csv running the script
./loadDecisionTableFile.sh [8443] [index_getjenny_english_0] [decision_table_file.csv]
and then you need to index the analyzer:
./postIndexAnalyzer.sh
In case you want to delete all states previously loaded you need to delete the decision table previously loaded running the script
./postDeleteAllDecisionTables.sh
1.5 Index the FAQs (optional)
TODO: You might want to activate the knowledge base for simple Question and Anwer.
1.6 Installation Test
Is the service working? But first: did you load a configuration file? If yes, try:
curl -X GET localhost:8888
Now try to ask question to the bot running the script:
./getNextResponseSearch.sh "contribute"
You should get:
[
{
"action":"",
"actionInput":{},
"analyzer":"bor(keyword(\"contribute\"))",
"bubble":"To contribute to <a href=\"http://git.io/*chat\">StarChat</a>, please send us a pull request from your fork of this repository.\n<br>Our concise contribution guideline contains the bare minimum requirements of the code contributions.\n<br>Before contributing (or opening issues), you might want to email us at starchat@getjenny.com.",
"conversationId":"1234",
"data":{
},
"failureValue":"",
"maxStateCount":0,
"score":1.0,
"state":"contribute",
"stateData":{
},
"successValue":"",
"traversedStates":[
"contribute"
]
}
]
If you look at the "analyzer" field, you'll see that this state is triggered when
the user types the contribute. The "bubble" field contains the response.
2. Development Envinroment
The easiest way to modify the StarChat source code, recompile and test changes is to:
- Install sbt
- Clone [StarChat repository] (https://github.com/GetJenny/starchat)
- Clone Starchat Docker as explained at 1.1
and running the commands
## Start ElasticSearch from docker preconfigured container
cd starchat-docker/
docker-compose up elasticsearch
## Compile and Run StarChat
cd starchat/
sbt compile run
Now StarChat is running and you can configure and test the installation as explained in Installation
3. Docker Image Creation for testing branches
If you want to generate a new docker image to be distributed you need to run in StarChat directory:
sbt dist
Enter the directory docker-starchat:
cd docker-starchat
You will get a message like Your package is ready in ...../target/universal/starchat-4ee.... .zip. Extract the packet into the docker-starchat folder:
unzip ../target/universal/starchat-4eee.....zip
ln -s starchat-4ee..../ starchat
The zip packet contains:
- a set of command line programs
starchat/binto run starchat and other tools. - a set of scripts to test the endpoints and as a complement for the documentation:
starchat/scripts/api_test/ - delete-decision-table: application to delete items from the decision table
- index-corpus-on-knowledge-base: application to index a corpus on knowledge base as hidden (to improve the language model)
- index-decision-table: application to index data on the decision table from a csv
- index-knowledge-base: application to index data into the knowledge base
- index-terms: application to index terms vectors
Review the configuration files starchat/config/application.conf and configure the language if needed (by default you have index_language = "english")
(If you are re-installing StarChat, and want to start from scratch see start from scratch.)
Start both startchat and elasticsearch:
docker-compose up -d
Now StarChat is running and you can configure and test the installation as explained in Installation
If you get org.elasticsearch.bootstrap.StartupException: ElasticsearchException[failed to bind service];
nested: AccessDeniedException[/usr/share/elasticsearch/data/nodes be sure that docker-starchat/elasticsearch is accessible to docker service.
Configuration of the chatbot (Decision Table)
With StarChat's Decision Table you can easily implement workflow-based chatbots. After the installation (see above) you only have to configure a conversation flow and eventually a front-end client.
NLP processing
NLP processing is of course the core of any chatbot. As you have noted in the CSV provided in the doc/ directory there are two fields defining when StarChat should trigger a state -analyzer and queries.
Queries
If the analyzer field is empty, StarChat will query Elasticsearch for the state containing the most similar sentence in the field queries. We have carefully configured Elasticsearch in order to provide good answers (e.g. boosting results where the same words appear etc), and results are... acceptable. But you are encouraged to use the analyzer field, documented below.
Analyzer
The analyzers are a Domain Specific Language which allow to put together various functions using logical operators.
Through the analyzers, you can leverage on various NLP algorithms included in StarChat and combine the results of those algorithms with other rules. For instance you might want to get into the state which asks for the email only if a variable "email" is not set. Or you want to escalate to a human operator after you detect swearing for three times. Or you want to escalate only on working days. You can do all that with the analyzers.
We can have a look at the simple example included in the CSV provided in the doc/ directory for the state forgot_password:
booleanAnd(keyword("password"),booleanOr(keyword("reset"),keyword("forgot")))
The analyzer above says the state must be triggered if the term "password" is detected together with either "reset" or "forgot".
Another example. Imagine we have a state called send-updates. In this state StarChat proposes the question "Where can we send you updates?". In the config file:
state | ... | bubble | ...
send-updates | ... | "Where can we send you updates?" |
In another state, called send-email, we have the anlyzer field with:
booleanAnd(lastTravStateIs("send-updates"), matchEmailAddress("verification_"))
this means send-email will be triggered only after send-updates (because of lastTravStateIs) and if an email address is detected (because of matchEmailAddress). This will also set the variable verification_email because the expression matchEmailAddress in case of success always sets such variable, with the expression's argument as prefix.
In addition to that, the expression sendVerificationEmail could be developed (we haven't) which accepts others arguments, for example:
sendVerificationEmail("verification_", "Email about Verification", "Here is your verification link %__temp__verification_link%)
In this case, the expression would
- extract an email address from the user's query
- set a variable
verification_emailwith such address - retrieve a verification link from some API
- put that link into the temporary variable
__temp__verification_link. - send an email with subject "Email about Verification" and body "Here is your..."
- return 1 in case of success
TODO It is fundamental here to build a set of metadata which allows any other component to receive all needed information about the analyzer. For instance, the sendVerificationEmail could have something like:
[
"documentation": "Send an email with subject and body. If successful returns 1.0 and sets the variables. If not returns 0 and does not set the variables."
"argument_list": ["'prefix' of the variable 'prefix_email'",
"Subject of the email to be sent", "Body of the mail"],
"created_variables": { // Variables it creates
"__temp__verification_link": "Link provided by the brand's API", //will after usage because starts with __temp__
"prefix_email": "email address"
},
"used_variables": { // Variables it expects to find in the state (none here)
}
How the analyzers are organized
The analyzer DSL building blocks are the expression. For instance,
or, and, keyword are all expressions.
Espressions are then divided into operators (or...) and atoms (keyword).
Expressions: Atoms
Presently, the keyword("reset") in the example provides a very simple score: occurrence of the word reset in the user's query divided by the total number of words. If evaluated agains the sentence "Want to reset my password", keyword("reset") will currently return 0.2.
TODO: This is just a temporary score used while our NLP library manaus is not integrated into the decision table.
These are currently the expression you can use to evaluate the goodness of a query (see DefaultFactoryAtomic and StarchatFactoryAtomic:
- keyword("pass.*"): as explained above, detects any word starting with "pass". Normalized.
- regex(regex): evaluate a regular expression, not normalized
- search(state-name): take a state name as argument, queries elastic search and returns the score of the most similar query in the field
queriesof the argument's state. In other words, it does what it would do without any analyzer, only with a normalized score -e.g.search("lost_password_state") - matchPatternRegex(regex): A generic pattern extraction analyzer, it extract named patterns matching a given regex. E.g., the following will match tree numbers separated by column:
[first,second,third](?:([0-9]+:[0-9]:[0-9]+)). If the regex matches, it will create the entries into the state variables dictionary. The string "10:11:12" will result in Map("first.0" -> "10", "second.0" -> "11", "third.0" -> "12"). The number at the end of the name is an index incremented for multiple occurrences of the pattern in the query - matchDateDDMMYYYY(prefix): parse a date in DDMMYYYY format and set
prefixday.0,prefixmonth.0,prefixyear.0. - existsVariable(variable-name): check whether a variable exists or not
- hasTravState(state-name): check if a state_name is present into the history of traversed states
- lastTravStateIs(state-name): check if the last traversed state is state_name
- prevTravStateIs(state-name): check if the last but one traversed state is state_name
- distance("forget.", ..., "pass."): score based on the (cosine) distance between the query and the list of words in the argument.
- checkDayOfMonth: Check if the current time is Equal, LessOrEqual, Less, Greater, GreaterOrEqual to the argument which is an integer between 1 and 31
- first argument is the day of the month: a number between 1 and 31
- second argument is the operator: any of Equal, LessOrEqual, Less, Greater, GreaterOrEqual
- third argument is the timezone: UTC, GMT, UT, CET, UTC+
, UTC- , GMT+ , GMT- , UT+ or UT- where N is a number between -18 and +18. Default is CET - checkDayOfWeek: Check if the current time is Equal, LessOrEqual, Less, Greater, GreaterOrEqual to the argument which is an integer between 1 (MONDAY) and 7 (SUNDAY)
- first argument is the day of the week: a number between 1 and 7
- second argument is the operator: any of Equal, LessOrEqual, Less, Greater, GreaterOrEqual
- third argument is the timezone: UTC, GMT, UT, CET, UTC+
, UTC- , GMT+ , GMT- , UT+ or UT- where N is a number between -18 and +18. Default is CET - checkHour: Check if the current time is Equal, LessOrEqual, Less, Greater, GreaterOrEqual to the argument time in EPOC
- first argument is the hour: a number between 0 and 23
- second argument is the operator: any of Equal, LessOrEqual, Less, Greater, GreaterOrEqual
- third argument is the timezone: UTC, GMT, UT, CET, UTC+
, UTC- , GMT+ , GMT- , UT+ or UT- where N is a number between -18 and +18. Default is CET - checkMinute: Check if the current minutes are Equal, LessOrEqual, Less, Greater, GreaterOrEqual to the first argument
- first argument is the minute: a number between 0 and 59
- second argument is the operator: any of Equal, LessOrEqual, Less, Greater, GreaterOrEqual
- third argument is the timezone: UTC, GMT, UT, CET, UTC+
, UTC- , GMT+ , GMT- , UT+ or UT- where N is a number between -18 and +18. Default is CET - checkMonth: Check if the current month is Equal, LessOrEqual, Less, Greater, GreaterOrEqual to the argument which is an integer between 1 (JANUARY) and 12 (DECEMBER)
- first argument is the month's number: an integer between 1 and 12
- second argument is the operator: any of Equal, LessOrEqual, Less, Greater, GreaterOrEqual
- third argument is the timezone: UTC, GMT, UT, CET, UTC+
, UTC- , GMT+ , GMT- , UT+ or UT- where N is a number between -18 and +18. Default is CET - checkTimestamp: Check if the current time is Equal, LessOrEqual, Less, Greater, GreaterOrEqual to the argument time in EPOC
- first argument is the timestamp: a timestamp in EPOC (in seconds)
- second argument is the operator: any of Equal, LessOrEqual, Less, Greater, GreaterOrEqual
- double: transform a string into a double, useful for score comparison (see, eq, lt, gt, lte, gte operators)
Expressions: Operators
Operators evaluate the output of one or more expression and return a value. Currently, the following operators are implemented (the the source code):
- boolean or: calles matches of all the exprassions it contains and returns true or false. It can be called using
bor - boolean and: as above, it's called with
band - boolean not: ditto,
bnot - conjunction: if the evaluation of the expressions it contains is normalized, and they can be seen as probabilities of them being true, this is the probability that all the expressions are all true (
P(A)*P(B)) - disjunction: as above, the probability that at least one is true (
1-(1-P(A))*(1-P(B))) - max: takes the max score of returned by the expression arguments
- reinfConjunction: conjuction which uses a 1.1 value instead of 1 as boolean true
- binarize: take the result of an expression output 1.0 if the score is > 0, 0.0 otherwise
- eq compare the score of two expression, output 1.0 if they are the same, 0.0 otherwise
- lt compare the score of two expression, output 1.0 if the first arg is less than the second, 0.0 otherwise
- gt compare the score of two expression, output 1.0 if the first arg is greater than the second, 0.0 otherwise
- lte compare the score of two expression, output 1.0 if the first arg is less or equal than the second, 0.0 otherwise
- gte compare the score of two expression, output 1.0 if the first arg is greater or equal than the second, 0.0 otherwise
Technical corner: expressions
Expressions, like keywords in the example, are called atoms, and have the following methods/members:
def evaluate(query: String): Double: produce a score. It might be normalized to 1 or not (setval isEvaluateNormalized: Booleanaccordingly)val match_thresholdThis is the threshold above which the expression is considered true whenmatchesis called. NB The default value is 0.0, which is normally not ideal.def matches(query: String): Boolean: calles evaluate and check agains the threshold...val rx: the name of the atom, as it should be used in theanalyzerfield.
Configuration of the answer recommender (Knowledge Base)
Through the /knowledgebase endpoint you can add, edit and remove pairs of question and answers used by StarChat to recommend possible answers when a question arrives.
Documents containing Q&A must be structured like that:
{
"id": "0", // id of the pair
"conversation": "id:1000", // id of the conversation. This can be useful to external services
"index_in_conversation": 1, // when the pair appears inside the conversation, as above
"question": "thank you", // The question to be matched
"answer": "you are welcome!", // The answer to be recommended
"question_scored_terms": [ // A list of keyword and score. You can use your own keyword extractor or our Manaus (see later)
[
"thank",
1.9
]
],
"verified": true, // A variable used in some call centers
"topics": "t1 t2", // Eventual topics to be associated
"dclass": "", // Optional field as a searchable class for answer
"doctype": "normal",
"state": "",
"status": 0
}
See POST /knowledgebase for an example with curl. Other calls (GET, DELETE, PUT) are used to get the state, delete it or update it.
Test the knowledge base
Just run the example in POST /knowledgebase_search.
Manaus
In the Q&A pair above you saw the field
question_scored_terms. Having good keywords improves enormously the
quality of the answer. You can of course put them by hand, or run a
software which extracts the keywords from the question. If you prefer
the latter, but don't have any, we provide
Manaus.
Manaus is still under development, but it's already included in the
Docker's installation of StarChat. When you launch docker-compose up
-d, you also launch a container with Manaus which analyzes all the
Q&A in the Knowledge Base, produces keywords and updates the field
question_scored_terms for all documents. The process is repeated evert
4 hour.
Manaus configuration
Have a look at the file docker-starchat/docker-compose.yml. For
Manaus to have good performance, you need to provide decent language
statistics. Update the file /manaus/statistics_data/english/word_frequency.tsv with a
word-frequency file with the following format:
1 you 1222421
2 I 1052546
3 to 823661
....
We have frequency file for more than 50 languages, but consider that the choice of good "prior distribution" of word frequency is crucial for any NLP task.
Technology
StarChat was design with the following goals in mind:
- easy deployment
- multi-tenancy: starchat can handle different KnowledBase and DecisionTable configurations
- horizontally scalability without any service interruption.
- modularity
- statelessness
How does StarChat work?
Workflow
Components
StarChat uses Elasticsearch as NoSQL database and, as said above, NLP preprocessor, for indexing, sentence cleansing, and tokenization.
Services
StarChat consists of the following REST resources.
Root
The root endpoint provides just an health check endpoint
SystemIndexManagement
The SystemIndexManagement set of endpoints provides a means to set up and manage the system tables.
IndexManagement
The IndexManagement REST endpoints allows to create new indexes for new instances (StarChat is multitenant).
LanguageGuesser
Offers endpoints to guess the language given a text.
QuestionAnswer type (same API syntax and semantic):
The following REST endpoints have the same syntax and semantic but they serve different needs.
KnowledgeBase
For quick setup based on real Q&A logs. It stores question and answers pairs. Given a text as input it proposes the pair with the closest match on the question field. At the moment the KnowledBase supports only Analyzers implemented on Elasticsearch.
PriorData
The prior data contains text to be used for extraction of statistics about terms and text. The data are used primarity for terms extraction (Manaus)
ConversationLogs
Endpoint to collect and store the conversation logs.
Tokenizer
Endpoint which exposes text tokenization functionalities.
Spellcheck
Endpoint which exposes spellcheck functionalities, the terms statistics are taken from the KnowledgeBase.
Term
Endpoint to store informations about terms: synonyms, antonyms and vectorial representation.
TermsExtraction
Exposes Manaus functionalities to extract significant terms from the text. It need data from the PriorData and the domain specific dataset (KnowledgeBase).
AnalyzersPlayground
Exposes REST endpoints to test the analyzers on the fly.
DecisionTable
The conversational engine itself. For the usage, see below.
Configuration of the DecisionTable
You configure the DecisionTable through CSV file. Please have a look at the CSV provided in the doc/ directory.
Fields in the configuration file are of three types:
- (R): Return value: the field is returned by the API
- (T): Triggers to the state: when should we enter this state?
- (I): Internal: a field not exposed to the API
And the fields are:
- state: a unique name of the state (e.g.
forgot_password) - execution_order: specify an order of evaluation for analyzers the lower is the number earlier is the evaluation of the state
- max_state_count: defines how many times StarChat can repropose the state during a conversation.
- analyzer (T,I): specify an analyzer expression which triggers the state
- query (T,I): list of sentences whose meaning identify the state
- bubble (R): content, if any, to be shown to the user. It may contain variables like %email% or %link%.
- action (R): a function to be called on the client side. StarChat developer must provide types of input and output (like an abstract method), and the GUI developer is responsible for the actual implementation (e.g.
show_button) - action_input (R): input passed to action's function (e.g., for
show_buttonscan be a list of pairs("text to be shown on button", state_to_go_when_clicked) - state_data (R): a dictionary of strings with arbitrary data to pass along
- success_value (R): output to return in case of success
- failure_value (R): output to return in case of failure
Client functions
In StarChat configuration, the developer can specify which function the front-end should execute when a certain state is triggered, together with input parameters. Any function implemented on the front-end can be called.
Example show button
- Action:
show_buttons - Action input:
{"buttons": [("Forgot Password", "forgot_password"), ("Account locked", "account_locked")]} - The frontend will call function:
show_buttons(buttons={"Forgot Password": "forgot_password","Account locked": "account_locked")
Example "buttons": the front-end implements the function show_buttons and uses "action input" to call it. It will show two buttons, where the first returns forgot_password and the second account_locked.
Example send email
- Action:
send_password_link - Action input:
{ "template": "Reset your password here: example.com","email": "%email%","subject": "New password" } - The frontend will call function:
send_password_link(template="Reset your password here: example.com.",email= "john@foo.com", subject="New password")
Example "send email": the front-end implements the function send_password_link and uses "action input" to call it. The variable %email% is automatically substituted by the variable email if available in the JSON passed to the StarchatResource.
functions for the sample csv
For the CSV in the example above, the client will have to implement the following set of functions:
- show_buttons: tell the client to render a multiple choice button
- input: a key/value pair with the key indicating the text to be shown in the button, and the value indicating the state to follow e.g.: {"Forgot Password": "forgot_password", "Account locked": "account_locked", "Specify your problem": "specify_problem", "I want to call an operator": "call_operator", "None of the above": "start"}
- output: the choice related to the button clicked by the user e.g.: "account_locked"
- input_form: render an input form or collect the input following a specific format
- input: a dictionary with the list of fields and the type of fields, at least "email" must be supported: e.g.: { "email": "email" } where the key is the name and the value is the type
- output: a dictionary with the input values e.g.: { "email": "foo@example.com" }
- send_password_generation_link: send an email with instructions to regenerate the password
- input: a valid email address e.g.: "foo@example.com"
- output: a dictionary with the response fields e.g.: { "user_id": "123", "current_state": "forgot_password", "status": "true" }
Ref: sample_state_machine_specification.csv.
Mechanics
- The client implements the functions which appear in the action field of the spreadsheet. We will provide interfaces.
- The client call the rest API "decisiontable" endpoint communicating a state if any, the user input data and other state variables
- The client receive a response with guidance on what to return to the user and what are the possible next steps
- The client render the message to the user and eventually collect the input, then call again the system to get instructions on what to do next
- When the "decisiontable" functions does not return any result the user can call the "knowledgebase" endpoint which contains all the conversations.
Scalability
StarChat consists of two different services: StarChat itself and an Elasticsearch cluster.
Scaling StarChat instances
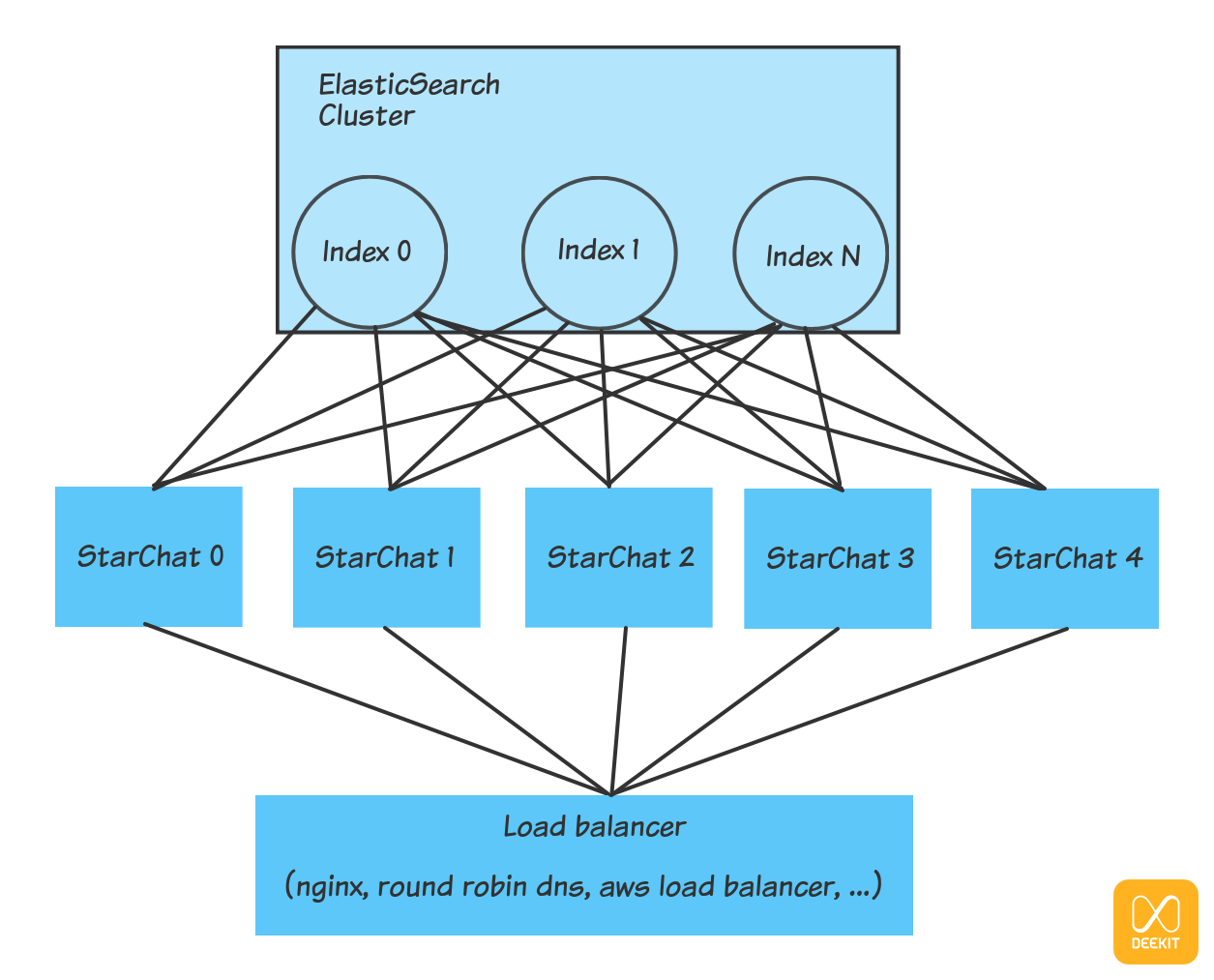
Since StarChat is stateless it can scale horizontally by replication. All the instances can access to all the configured indexes on ElasticSearch and can answer to the APIs call enforcing authentication and authorization rules. A load balancer will be responsible of scheduling the requests to the instances transparently.
In the diagram below, a load balancer forward requests coming from the front-end to StarChat instances which access to the indices created on the Elasticsearch cluster.
Scaling Elasticsearch
Similarly, Elasticsearch can easily scale horizontally adding new nodes to the cluster, as explained in Elasticsearch Documentation.
Security
StarChat is a backend service which supports authentication and authorization with salted SHA512 hashed password and differentiated permissions.
The admin hashed password and salt are stored on the StarChat configuration file, the user credentials (hashed password, salt, permissions) are instead saved on ElasticSearch (further backend for authentication/authorization can be implemented by specialization of the Auth. classes).
StarChat support TLS connections, the configuration file allow to choose if the service should expose an https connection or an http connection or both. In order to use the https connection the user must do the following things:
- obtain a pkcs12 server certificate from a certification authority or create a self signed certificate
- save the certificate inside the folder
config/tls/certs/e.g.config/tls/certs/server.p12 - set the password for the certificate inside the configuration file
- enable the https connection setting to true the https.enable property of the configuration file
- optionally disable the http connection setting to false the http.enable property of the configuration file
Follows the block of the configuration file which is to be modified as described above in order to use https:
https {
host = "0.0.0.0"
host = ${?HOST}
port = 8443
port = ${?PORT}
certificate = "server.p12"
password = "uma7KnKwvh"
enable = false
}
http {
host = "0.0.0.0"
host = ${?HOST}
port = 8888
port = ${?PORT}
enable = true
}
StarChat come with a default self-signed certificate for testing, using it for production or sensitive environment is highly discouraged as well as useless from a security point of view.
Indexing terms on term table
The following program index term vectors on the vector table:
sbt "run-main com.getjenny.command.IndexTerms --inputfile terms.txt --vecsize 300"
The format for each row of an input file with 5 dimension vectors is:
hello 1.0 2.0 3.0 4.0 0.0
You can use your ad-hoc trained vector model (as we do) otherwise you can use the google word2vec models trained on google news. You can find a copy of the elasticsearch index with a pre-loaded google news terms.
Test
Unit tests
A set of unit test is available using docker-compose to set up a backend, the command to run tests is:
sbt dockerComposeUp ; sbt test ; sbt dockerComposeStop
test scripts with sample API calls
- A set of test script is present inside scripts/api_test
Troubleshooting
Docker: start from scratch
You might want to start from scratch, and delete all docker images.
If you do so (docker images and then docker rmi -f <java/elasticsearch ids>) remember that all data for the
Elasticsearch docker are local, and mounted only when the container is up. Therefore you need to:
cd docker-starchat
rm -rf elasticsearch/data/nodes/
docker-compose: Analyzers are not loaded
StarChat is started immediately after elasticsearch and it is possible that elasticsearch is not ready to respond to REST calls from StarChat (i.e. an index not found error could be raised in this case).
Sample error on the logs:
2017-06-15 10:37:22,993 >10:37:22.992UTC ERROR c.g.s.s.AnalyzerService(akka://starchat-service) com.getjenny.starchat.services.AnalyzerService(akka://starchat-service) - can't load analyzers: [jenny-en-0]
IndexNotFoundException[no such index]
In order to avoid this problem you can call the services one by one:
docker-compose up elasticsearch # here wait elasticsearch is up and running
docker-compose up starchat # starchat will retrieve the Analyzers from elasticsearch
In alternative is possible to call the command to load/refresh the Analyzers after the docker-compose command:
curl -v -H "Content-Type: application/json" -X POST "http://localhost:8888/decisiontable_analyzer"
Docker: Elasticsearch required size of virtual memory
If elasticsearch complains about the size of the virtual memory:
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
elastisearch exited with code 78
run:
sysctl -w vm.max_map_count=262144
Docker: Elasticsearch required open files limit
If elasticsearch complains about the limit of the open files:
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
you should increase the limit of max open files. Here you can find instruction for Ubuntu 18.04
sbt dist
In case you have ununderstandable errors from sbt dist, like this one:
[error] null
[error] scala.tools.nsc.typechecker.Typers$Typer.typed1(Typers.scala:5239)
[error] scala.tools.nsc.transform.Erasure$Eraser.typed1(Erasure.scala:789)
[error] scala.tools.nsc.typechecker.Typers$Typer.typed(Typers.scala:5617)
[error] scala.tools.nsc.transform.Erasure$Eraser.adaptMember(Erasure.scala:714)
[error] scala.tools.nsc.transform.Erasure$Eraser.typed1(Erasure.scala:789)
try to increase the amount of memory given to the jvm, adding javacOptions += "-Xss2048K" in build.sbt just above the scalacOptions.